
why stream of data conciousness
The reason why Stream of data consciousness came to life could be tentatively formalized in the following mock logistic regression model:
$$log(\frac{p_{blogging}}{1-p_{blogging}}) = \beta_1 \cdot stayathome + \beta_2 \cdot datascience + \beta_3 \cdot nerdiness + \epsilon$$
Given that you are reading this blog the resulting model effects plot tells something about the author: Mario De Toma.
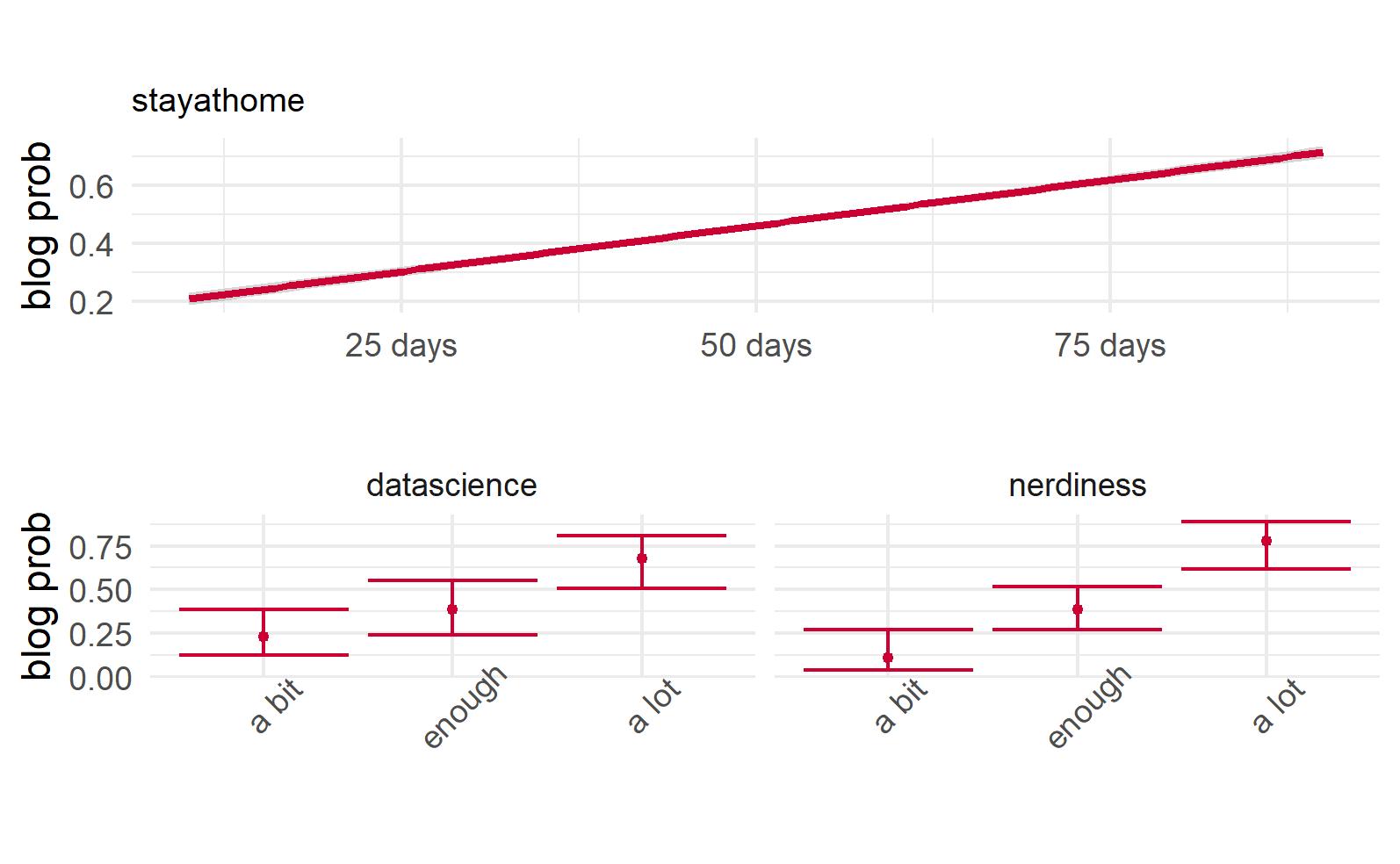
The author lives in Lombardy, Italy, which was under hard lockdown due to COVID19 in first half of 2020 and he is enthusiastic about data science. Furthermore he shows nerdish psychological traits at some extent.
the blog
“Stream of data consciousness” blog is a collection of data analysis. Each post represents a serious tentative to answer relevant questions (at least for the author) through data science.
Posts are not always an easy read: while the industry follow the path called “democratize” data science, content posted assumes readers have a certain degree of data science awareness.
Nonetheless the author is eager to discuss any content and to share analysis procedures and code with anyone who shows genuine interest.
contact and support the author
If you want to analyze stream of data consciousness posts further in depth you can schedule a meeting with the author.
In any case if you find any of the posts valuable, please let the author know!
You can also support the author buying him a coffee on Ko-fi!

Thanks for reading Stream of data consiousness!
Mario De Toma